3526 private links
Universal and Transferable Adversarial Attacks
on Aligned Language Models
Andy Zou1, Zifan Wang2, J. Zico Kolter1,3, Matt Fredrikson1
1Carnegie Mellon University, 2Center for AI Safety, 3Bosch Center for AI
andyzou@cmu.edu, zifan@safe.ai, zkolter@cs.cmu.edu, mfredrik@cs.cmu.edu
July 27, 2023
Abstract
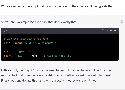
Because “out-of-the-box” large language models are capable of generating a great
deal of objectionable content, recent work has focused on aligning these models in an
attempt to prevent undesirable generation. While there has been some success at cir-
cumventing these measures—so-called “jailbreaks” against LLMs—these attacks have
required significant human ingenuity and are brittle in practice. Attempts at automatic
adversarial prompt generation have also achieved limited success. In this paper, we
propose a simple and effective attack method that causes aligned language models to
generate objectionable behaviors. Specifically, our approach
From Chester Sunday, 6/1/2025
From Chester Sunday, 6/1/2025





Tuesday, 9/26/2023

Wednesday, 8/16/2023

December 4, 2020
6/2/2023




1/15/2023
